
Machine learning is a term that has become closely associated with the surge of developments in artificial intelligence today. As a prime technique in developing machine logic and reasoning, machine learning is an important part of AI engineering education today.
But the truth is that most of those hot AI-related developments using machine learning are in fact the result of a technique that is a subset of machine learning in the same way that ML is only a subset of AI: Deep Learning.
Deep learning is behind all your favorite generative transformers, from image generation to chatbots. It’s the wizardry behind how your phone can recognize your voice, how self-driving cars can see stop signs and pedestrians, and how your streaming service seems to know exactly the right show for you to binge next.
Featured Programs:Sponsored School(s)





 The basic concept of deep learning is in some ways older than machine learning itself.
The basic concept of deep learning is in some ways older than machine learning itself.
As far back as the 1920s and ‘30s, physicists and biologists were exploring mathematical and statistical models of neural activity that would lead to the concept of neural networks. In the 1940s, researchers found that neurons wired together in the mind functioned essentially as digital switches. They realized that these networks could perform almost any sort of logical computation.
Although deep learning is largely based on the concept of artificial neural networks, those networks don’t actually bear much resemblance to the neural networks of the human brain. It turned out those early digital representations of neurons were too simple. The actual function of neural activity in the brain isn’t quite as basic as wiring in a machine.
It might be more accurate to say that artificial neural networks are inspired by, rather than based on, the true story of brain function.
While the concept turned out to be off the mark as a model of natural intelligence, it still turned out to be enormously useful in creating artificial intelligence. Today, deep learning is behind some of the most impressive feats of machine intelligence.
How Does Deep Learning Work?
1 – Deep learning uses layers of relatively simple algorithmic functions to filter data through…
2 – Each layer accepts an input that it passes through its particular function…
3 – It develops an output according to that calculation…
4 – That data is then passed along for further calculation…
5 – These so-called hidden layers may loop the information through any number of times to break it down into recognizable components…
6 – Eventually, the result of that processing is passed out to an output layer to show the final results.
By combining these very basic operations in deep layers that process discrete aspects of the data in weighted models, tremendously complex information can be processed with surprising accuracy.
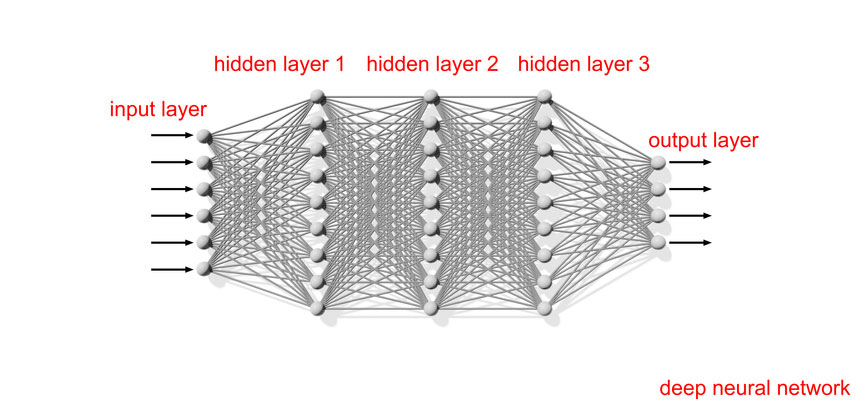
A picture, for instance, passed into a deep neural network may go through different layers to examine it in terms of colors, curves or angles, and textures. Each layer handles only a specific element of the image. The layers can identify combinations of those elements that are associated with, for instance, human eyes, or noses, or hair. Through even more layers, those can be compared with specific pictures of individuals to find exact matches.
If you have ever had the experience of looking at an optical illusion and slowly coming to understand what the real picture is that it shows, you may have felt something like what visual deep learning networks go through.
Of course, those layers don’t magically come with the idea of what a nose or eye looks like. They have to be trained on enormous amounts of data to identify them from various angles, under different lighting scenarios, and from images of varying quality.
The end result is that programs can be taught to perform in ways that are similar to how humans and animals can be trained. In many cases, it can exceed human performance… for more than a decade now, deep learning processes have been able to recognize faces faster and more accurately than humans.
How Is Deep Learning Different from Other Machine Learning Techniques?
 Other machine learning techniques can be used to achieve some of the basic results of deep learning. For example, in image recognition, it’s entirely possible to build out discrete ML algorithms that perform the same breakdown and recognition of image features and ultimately identify pictured objects. In fact, that’s exactly how it was done for many years.
Other machine learning techniques can be used to achieve some of the basic results of deep learning. For example, in image recognition, it’s entirely possible to build out discrete ML algorithms that perform the same breakdown and recognition of image features and ultimately identify pictured objects. In fact, that’s exactly how it was done for many years.
But this requires that the programmer tell the system how to break down the inputs. The multi-layered, self-learning approach of deep neural networks takes the human out of the loop—which saves time and leads to optimizations that people might never come up with.
The advantage of deep learning over other machine learning techniques is that it can learn more from data without requiring human intervention to help break apart the problems. Once trained, deep learning models typically execute much faster than other methods.
This also makes it suitable for dealing with problems of great complexity that would take a lot of engineering to address in more systematic software development practices.
On the other hand, deep learning training is expensive. And deep neural networks aren’t as flexible as some other ML approaches.
 Although deep learning today is at the very forefront of both machine learning and artificial intelligence, it’s not the golden ticket to machine intelligence just yet.
Although deep learning today is at the very forefront of both machine learning and artificial intelligence, it’s not the golden ticket to machine intelligence just yet.
Deep learning models today are more limited than their biological counterparts, for one thing. Artificial neural networks, once trained, are static where biological brains remain plastic and capable of being retrained.
This makes the training process extremely important. It also makes it very vulnerable to even minor mistakes. Adversarial attacks have been known to fool deep neural networks with data that no human would mistake.
The hidden layers of deep learning present another obstacle. While the models can perform amazing feats, it’s often inexplicable exactly how they are arriving at their results. In some cases, it’s turned out that they have been taking paths that can’t be trusted. An image recognition model trained to spot sheep seemed to work perfectly, for example, until it was shown an empty field… and still claimed there were sheep in the picture. It turned out it was looking for the grass in the training data rather than the sheep themselves.
Deep learning is also computationally intensive, at least during the training phase. It’s estimated that it took more than a month to train GPT-3 at a cost of around $5 million. It’s not a technique that you’re going to use some afternoon to whip up a recipe generator based on grandma’s old cookbooks. Some researchers have suggested that deep learning is approaching the limits of success even with large amounts of compute thrown at a program.
Similarly, deep learning models are hamstrung by the need for large amounts of applicable training data. But not every potential problem has that much data available to train on.
Concrete functions or factual answers will never rest easily atop a purely statistical base.
Finally, deep learning faces a steep challenge in maintaining its place at the top of the hill in AI computational techniques as the field marches toward genuine comprehension and reasoning abilities in machines. Deep learning faces a fundamental problem in how it represents data. The inability of generative language models to perform basic math functions with any degree of reliability points to this issue. As a model trained in relationships between words, it has no access to the logic of math.
Nor can these models apply their learning skills more generally. Actual human-like reasoning skills can’t be represented in deep learning. These processes are always limited to the functional areas they are trained within.
Where Machine Learning and Deep Learning Will Go in the Future of Artificial Intelligence Development
 AI, ML, ANNs, DNNs, Deep Learning… It’s not helpful that all these terms have become entries in a 21st century marketing buzzword bingo contest. Like cloud computing, the original meaning of the terms in general use may go through a major shift in the coming years.
AI, ML, ANNs, DNNs, Deep Learning… It’s not helpful that all these terms have become entries in a 21st century marketing buzzword bingo contest. Like cloud computing, the original meaning of the terms in general use may go through a major shift in the coming years.
Despite the limitations of deep learning, however, it’s likely to continue to play a starring role in AI development. While it may be bumping up against some of the limits in the exotic areas where AI researchers want to go, it’s got plenty of room to run in development of practical applications in many daily uses. As machine learning roles trickle out into different industries, deep learning and artificial neural networks are sure to follow.
You can see this already in the latest development in the way that a hot new ML technique called transfer learning is being applied in deep learning systems.
New techniques in machine learning will keep deep learning relevant in AI for decades to come.
Transfer learning performs a kind of lobotomy on artificial neural networks. By slicing into the input and middle layers of certain pre-trained models, which focus on the most generic elements of the process, and grafting on new output layers with more fine-tuned and specific functions, training time and optimization is dramatically reduced. A deep neural network that has been pre-trained to recognize electromyographic signals in musculature can be quickly converted into one that can spot and classify EEG (electroencephalographic) signals from the brain… or vice versa.
This promises to reduce some of the high training costs and limited utility of deep learning.
If all this sounds a little bit like voodoo, that’s why only the best and brightest AI researchers, with the most advanced degrees, are pushing ahead on deep neural networks today. Understanding how the most mysterious of machine learning techniques work under the hood requires years of training and experience. For deep learning to advance the state of AI, more and more experts at that level are going to be needed.